2. Clustering#
2.1. What is a Cluster?#
Each server running a quasardb daemon is called a node. By itself, a node can provide fast key-value storage for a project where a SQL database might be too slow or impose unwanted design limitations.
However, the real power of a quasardb installation comes when multiple nodes are linked together into a cluster. A cluster is a peer-to-peer distributed hash table based on Chord . In a cluster, quasardb nodes self-organize to share data and handle client requests, providing a scalable, concurrent, and fault tolerant database.
2.2. Stabilization#
Stabilization is the process during which nodes agree on their position in the cluster. Stabilization happens when bootstrapping a cluster, in case of failure, or when adding nodes. It is transparent and does not require any intervention. A cluster is considered stable when all nodes are ordered in the ring by their respective ids.
In most clusters, the time required to stabilize is extremely short and does not result in any modification of order of nodes in the ring. However, if one or several nodes fail or if new nodes join the cluster, stabilization also redistributes the data between the nodes. Thus the stabilization duration can vary depending on the amount of data to migrate, if any.
Nodes periodically verify their location in the cluster to determine if the cluster is stable. This interval can vary anywhere from 1 second up to 2 minutes. When a node determines the cluster is stable, it will increase the duration between each stabilization check. On the contrary, when the cluster is determined to be unstable, the duration between stabilization checks is reduced.
2.3. Adding a Node to a Cluster#
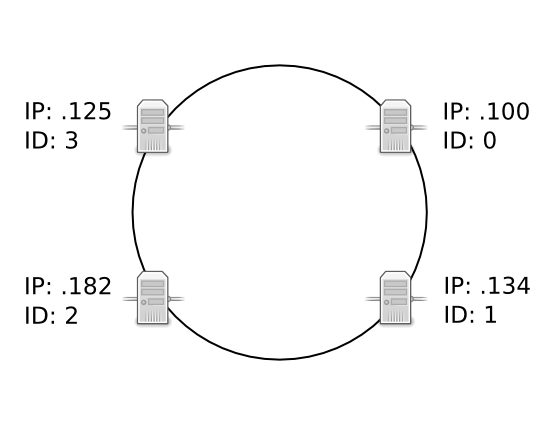
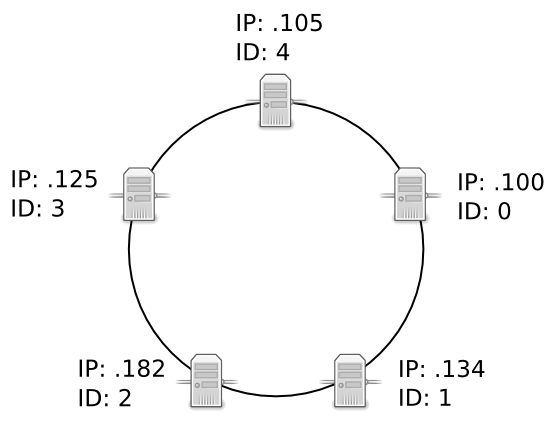
To add a new node to the cluster, all you need to do is tell the new QuasarDB node to bootstrap using the IP address of one of the existing nodes in the cluster. Assuming we have the following four-node cluster, with IPs 192.168.1.100, 192.168.1.125, 192.168.1.134 and 192.168.1.182:
If we would like to add a new node, 192.168.1.105, we would provide it with a bootstrap IP of one of the other nodes in the cluster. You can do this by setting the local.chord.bootstrapping_peers parameter in the configuration file:
"chord": {
"bootstrapping_peers": ["192.168.1.100:2836"]
}
For redundancy, you can add more than one peer to bootstrap from.
Once the new node is started with this configuration, this will happen:
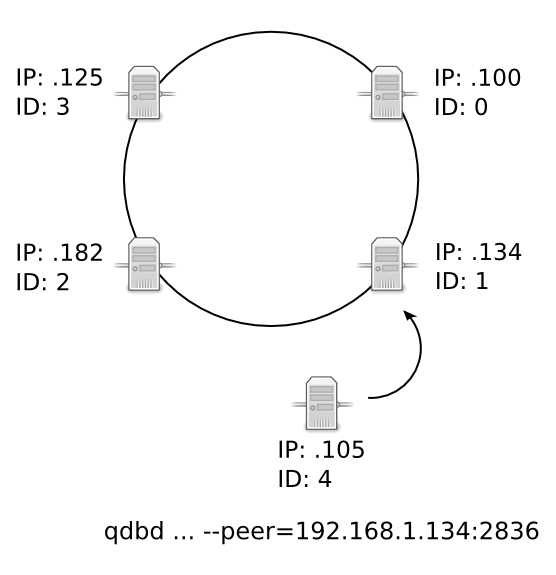
A fifth node is created and peered to the node at IP address 192.168.1.134. The fifth node connects, then downloads the configuration of the cluster, overwriting its global parameters with the cluster’s global parameters. This ensures that global parameters are consistent across the cluster, which is important for options like replication and persistence, where disparate parameters between nodes could cause unwanted behavior or data loss.
Once the node has received and applied the global parameters, the cluster begins the three-step process of Stabilization, where nodes validate their position in the ring, transfer data, and then update the topology.
Note that in this example, the fifth node assigned itself the unique ID of 4. In a production environment, the IDs are randomized hashes. In the unlikely event that a new node assigns itself an ID that is already taken by another node in the cluster, the new node will abort the join and stabilization process. The cluster remains unchanged.
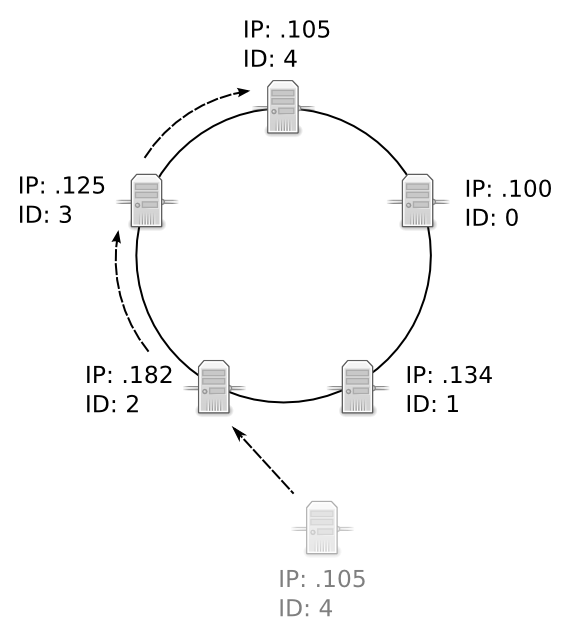
The fifth node uses the predecessor and successor values of its neighbor nodes to move itself to its appropriate location within the cluster. In this example, it moves until it has a predecessor of 3 and a successor of 0.
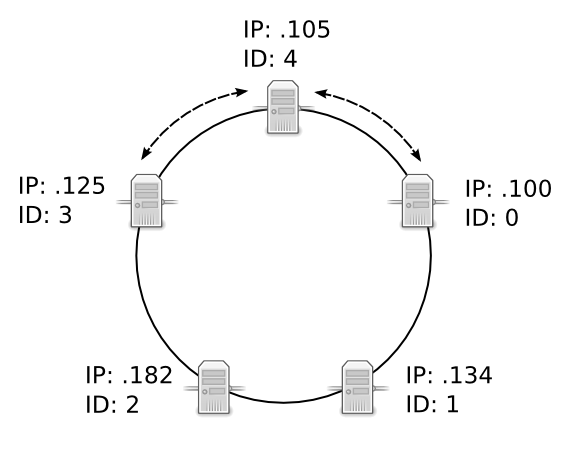
Once the node has found a valid predecessor and successor, it will download the data for which it is responsible, without joining the cluster. From a resource point of view, this is equivalent to one client downloading a range of data from the cluster.
Tip
Add nodes when activity is low to limit disruption.
During the period, the cluster is fully operational and clients are unaware that a node is joining the cluster.
For more information on data migration, see Data Migration.
Once the download is complete, the node will join the cluster, and download additional data that may have been added since it started to join the cluster.
During this period, some nodes may be unavailable, namely the predecessor, the successor, and the node that was added. This hand-over rarely exceeds one minute.
After the node has joined the cluster, nodes may elect to remove data that has been migrated to the new node, according to the replication policy of the cluster.
2.4. Removing a Node from a Cluster#
When a node is removed through a clean shutdown, it informs the other nodes in the ring on shutdown. The other nodes will immediately re-stabilize the cluster. If data replication is disabled, the entries stored on the node are effectively removed from the database. If data replication is enabled, the nodes with the duplicate data will serve client requests.
When a node is removed due to a node failure, the cluster will detect the failure during the next periodic stabilization check. At that point the other nodes will automatically re-stabilize the cluster. If data replication is disabled, the entries stored on the node are effectively removed from the database. If data replication is enabled, the nodes with the duplicate data will serve client requests.
Entries are not migrated when a node leaves the cluster, only when a node enters the cluster.
2.5. Recovering from Node Failure#
When a node recovers from failure, it needs to reference a node within the ring to rejoin the cluster. The configuration for the first node in a ring generally does not reference other nodes, thus, if the first node of the ring fails, you may need to adjust its configuration file to refer to an operational node.
If following a major network failure, a cluster forms two disjointed rings, the two rings will be able to unite again once the underlying failure is resolved. This is because each node “remembers” past topologies.
The detection and re-stabilization process surrounding node failures can add a lot of extra work to the affected nodes. Frequent failures will severely impact node performance.
Tip
A cluster operates best when more than 90% of the nodes are fully functional. Anticipate traffic growth and add nodes before the cluster is saturated.
2.6. Nodes IDs#
Each node is identified by an unique 256-bit number: the ID. If a node attempts to join a cluster and a node with a similar ID is found, the new node will exit the cluster.
In quasardb 2.0 nodes ID are either automatic, indexed or manual. The syntax is as such:
automatic: auto
indexed: current_node/total_node (e.g.
3/8for the third node of an 8-node cluster)manual: a 256-bit hexadecimal number grouped by 64-bit blocks (e.g
2545ef-35465f-87887e-5354)
Users are strongly encouraged to use the indexed ID generation mode. In indexed mode, quasardb will generate the ideal ID for a node given it’s relative position. For example, if you have a 4 nodes clusters, each node should be given the following id:
node 1 -
1/4node 2 -
2/4node 3 -
3/4node 4 -
4/4If you want to reserve ID space to allow the cluster to grow to 32 nodes without changing all ids, you should then use the following numbering
node 1 -
1/32node 2 -
9/32node 3 -
17/32node 4 -
25/32
The ideal IDs are equidistant from each-other, for optimal key-space value and that’s exactly what indexed mode computes.
If you wish to manually supply the nodes ID of your cluster, the following table gives a list of possible good IDs for a given cluster size:
Cluster size |
Suggested IDs |
|---|---|
02 |
|
03 |
|
04 |
|
05 |
|
06 |
|
07 |
|
08 |
|
09 |
|
10 |
|
11 |
|
12 |
|
13 |
|
14 |
|
15 |
|
16 |
|