3. Data Storage#
3.1. Where are Entries Stored in the Cluster?#
When an entry is added to the cluster, it is assigned a unique ID. This ID is a SHA-3 of the alias. The entry is then placed on the node whose ID is the successor of the entry’s ID. If replication is in place, the entry will be copied to other nodes for redundancy.
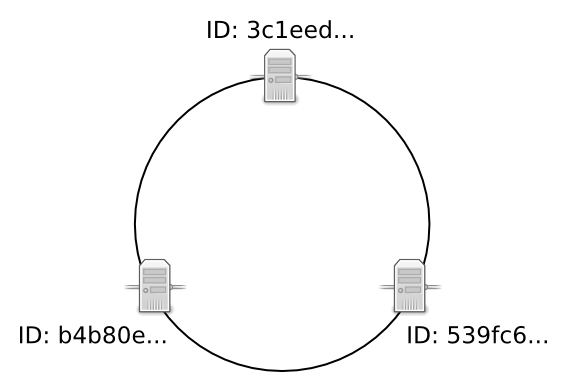
For example, here is a three node cluster. The nodes have UUID identifiers beginning with 3c1eed, 539fc6, b4b80e, respectively.
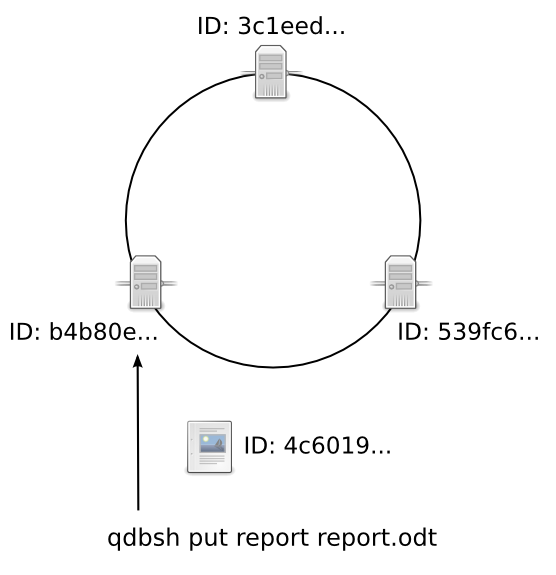
A client (qdbsh) puts a file on the b4b80e node. quasardb computes the file’s UUID as “4c6019…”.
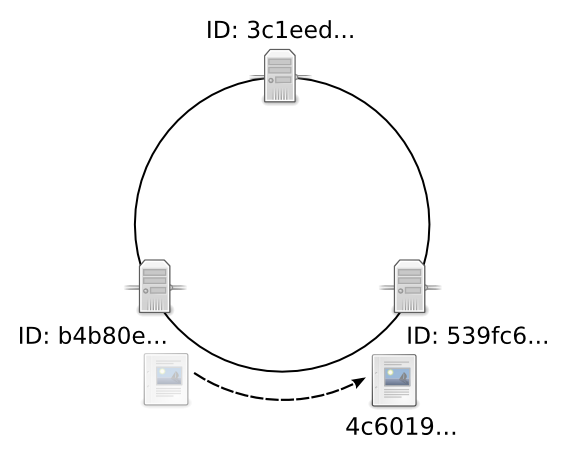
quasardb compares the UUIDs of each node to the UUID for the new entity. Because the new entity’s UUID begins with 4, its successor is 539fc6. The file is stored on the 539fc6 node.
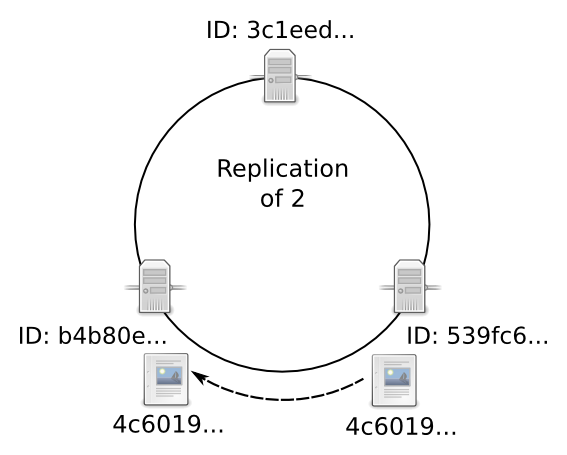
If the cluster is configured with a Data replication value of 2, a copy of the file is also stored on the b4b80e node. If the cluster is configured with a data replication value of 3, a copy of the file is stored on each node.
When nodes are added to the cluster, this adds new node UUIDs. Data is automatically migrated to the new successor during stabilization. For more information, see migration and stabilization.
Since the location of the entry depends on the order of nodes in the ring, exact control of the entry’s location can be done by setting each node’s ID in its configuration file. However, it is recommended to let quasardb set the node ID in order to prevent collisions.
3.2. Where are Entries Stored in a Node?#
Each node saves its data in its “root” directory, determined by its configuration file or the global parameter received from the cluster. By default this is the db directory under the quasardb daemon’s working directory.
quasardb has three persistence modes:
Transient: data is not stored on disk and will be lost if the node shuts down
RocksDB : an open source LSM-Tree store written by Facebook and based on LevelDB. Any software that is RocksDB compatible can process the quasardb database file.
Entries are usually stored “as is”, unmodified within the database. Data may be compressed for efficiency purposes, but this is transparent to the client and is never done to the detriment of performance.
Entries are often kept resident in a write cache so the daemon can rapidly serve a large amount of simultaneous requests. When a user adds or updates an entry on the cluster the entry’s value may not be synced to the disk immediately. However, quasardb guarantees the data is consistent at all times, even in case of hardware or software failure.
If you need to guarantee that every cluster write is synced to disk immediately, disable the write cache by setting the “sync” configuration option to true. Disabling the write cache may have an impact on performance.
3.3. Caching Strategy#
QuasarDB uses an LRU-2 (Least Recently Used, second chance) eviction policy with a configurable shard count ranging from 2 to 1024 (powers of two only). Sharding improves concurrency by reducing lock contention and allows parallel eviction decisions. The default of 8 shards strikes a balance between eviction quality and throughput for most workloads.
Note
Changing the shard count should only be done in an environment where the performance impact can be accurately measured, as both too few and too many shards can degrade efficiency.
3.3.1. LRU-2 Mechanics#
Two-timestamp promotion New entries track a single access timestamp and are considered lower priority for retention. When accessed again, they gain a second timestamp, making them eligible for longer retention compared to single-timestamp entries.
Ghost list Evicted entries are placed into a ghost list with their last access time. If re-accessed, they are resurrected with their prior timestamps, avoiding the “never promoted” issue that can occur if entries are evicted before a second access.
Eviction priority Among all candidates, single-timestamp entries are evicted first, followed by the least recently used among two-timestamp entries.
3.3.2. Eviction Trigger#
Eviction is governed by the allocator’s memory usage, not entry count. The allocator tracks usage precisely to the byte and exposes it via a single atomic read, ensuring accurate, contention-free eviction decisions. When usage approaches the configured memory limit, shards independently evict entries according to LRU-2 policy until usage returns below threshold.
3.3.3. Write-Through Option#
When writing to the cluster, the client may specify a ``write through`` flag. In this mode, the data is written directly to persistent storage and not cached locally, ensuring that the cache is reserved for read-heavy, reusable data rather than transient writes.
3.3.4. Scan Resistance#
The LRU-2 approach is scan resistant — short-term sequential access patterns (e.g., full table scans) do not flood the cache with single-use entries. Since new entries require a second access to be promoted, data touched only once is quickly evicted, preserving cache space for genuinely hot items.
3.3.5. Metrics and Observability#
Several cache-related metrics are exposed in the system statistics, including:
Hit rate – ratio of lookups served from the cache.
Promotion count – number of entries upgraded from one timestamp to two.
Eviction count – total entries removed from the cache.
These metrics allow operators to monitor efficiency, detect anomalies, and tune shard counts or memory limits with empirical data.
3.4. Cache configuration#
The daemon will start to evict entries when the memory usage reaches the soft limit. It will stop all processing and evict has much as it can when the process memory usage hits the hard limit. When QuasarDB evicts entries, it will throttle down queries to prevent a situation where users would load data faster than QuasarDB could evict it.
Thus, the memory usage is kept between the soft and the hard limit, possibly below the soft limit.
The memory usage measurement is based on the process size for the hard limit, and the allocator usage for the soft limit, which means that file system caches, and persistence layer caches are included in the hard limit measurement.
By default, the hard limit will be 80% of the physical RAM present on the machine, and the soft limit will be 75% of the hard limit.
On a machine with 64 GiB of RAM, the hard limit will thus be around 51 GiB, and the soft limit will be 38 GiB.
Each parameter can be configured independently, the hard limit must always be greater than the soft limit.
Ideally, you want your working set to fit in memory. The working set for a single node is close to the total working set divided by the number of nodes.
Note
The cache size has a huge impact on performance. Your QuasarDB solutions architect will be happy to assist you in finding the optimal setting for your usecase.
3.4.1. Transient mode#
Transient mode disables data storage altogether, transforming quasardb into a pure in-memory database. This mode is designed exclusively for automated testing environments and is not suitable for production use.
In transient mode:
Write performance may increase
Read performance will be slower due to less efficient indexing
Memory usage may be reduced
Disk usage will be significantly lowered
But:
Entries evicted from memory will be lost (see Memory Cache and Eviction)
Double-ended queues may be undefined due to eviction if you reach the memory limit.
Node failure may imply irrecoverable data loss
Node and cluster statistics will not be recorded
Entries cannot be iterated upon
For configuration instructions, see Transient Storage Engine in Configuration.
3.4.2. Persistent read cache#
A persistent read cache buffers data from a – possibly remote - storage into a faster, local storage. This can greatly improve performance by optimizing I/O.
The persistent cache is used to buffer reads only; it will not buffer writes to the remote storage, and thus, has no impact on consistency.
The persistent read cache is disabled by default. The persistent read cache should only be used on a storage device that is significantly faster than the main storage to show benefits.
3.4.3. Cloud storage#
QuasarDB supports storing your data in the cloud, or more precisely, use an object store such as AWS S3 as a backend in lieu of an attached file system.
Two main modes of operations are supported:
Data is kept in a local storage and copied to the cloud. When the data is not available locally, it will be fetched from the cloud.
Data is deleted locally as soon as it’s uploaded into the cloud. When the data is not available locally, it will be fetched from the cloud.
QuasarDB will store the data in the specified bucket and apply an optional prefix path to the db path used locally.
Caveats:
It is expected that the QuasarDB instance will run within the same region.
Concurrent QuasarDB instances cannot access the same stored database (e.g. bucket + path).
3.5. Data Migration#
Data migration is the process of transferring entries from one node to another for the purpose of load balancing. Not to be confused with Data replication.
Note
Data migration is always enabled.
Data migration only occurs when a new node joins the cluster. Nodes may join a cluster when:
The administrator expands the cluster by adding new nodes
A node recovers from failure and rejoins the cluster
3.5.1. Migration Process#
At the end of each stabilization cycle, each node requests entries that belong to it from its successor and its predecessor.
For example:
Node N joins the cluster by looking for its successor, Node S.
N stabilizes itself, informing its successor and predecessor of its existence.
When N has both predecessor P and successor S, N request both of them for the [P; N] range of keys
P and S send the requested keys, if any, one by one.
Note
Migration speed depends on the available network bandwidth, the speed of the underlying hardware, and the amount of data to migrate. Therefore, a large amount of data (several gigabytes) on older hardware may negatively impact client performance.
During migration, nodes remain available and will answer to requests. However, since migration occurs after the node is registered, there is a time interval during which some entries are being moved to their nodes. These entries may be temporarily unavailable.
Failure scenario:
Node N joins the ring and connects itself with its predecessor, Node P, and its successor Node S.
Meanwhile, a client looks for the entry E. Entry E is currently stored on Node S, but the organization of the cluster now says the successor is Node N.
Because Node N can be found in the ring, the client correctly requests Entry E from Node N.
N answers “not found” because Node S has not migrated E yet.
Entry E will only be unavailable for the duration of the migration and does not result in a data loss. A node will not remove an entry until the peer has fully acknowledged the migration.
Tip
To reduce the chance of unavailable data due to data migration, add nodes when cluster traffic is at its lowest point.
3.6. Data replication#
Data replication is the process of duplicating entries across multiple nodes for the purpose of fault tolerance. Data replication greatly reduces the odds of functional failures at the cost of increased disk and memory usage, as well as reduced performance when adding or updating entries. Not to be confused with Data Migration.
Note
Replication is optional and disabled by default, but is highly recommended for production environments (see our documentation on how to configure replication).
3.6.1. Principle#
Data is replicated on a node’s successors. For example, with a factor two replication, an entry will be stored on its primary node and on that node’s successor. With a factor three replication, an entry will be stored on its primary node and on its two following successors. Thus, replication linearly increases disk and memory usage.
Replication is done synchronously as data is added or updated. The call will not successfully return until the data has been stored and fully replicated across the appropriate nodes.
When a node fails or when entries are otherwise unavailable, client requests will be served by the successor nodes containing the duplicate data. In order for an entry to become unavailable, all nodes containing the duplicate data need to fail simultaneously. For more information, see Impact on reliability.
3.6.2. How replication works with migration#
When a new node joins a ring, data is migrated (see Data Migration) to its new host node. When replication is in place, the migration phase also includes a replication phase that consists in copying entries to the new successors. Thus, replication increases the migration duration. However, during this period, if the original entry is unavailable, the successor node will respond to client requests with the duplicate data.
3.6.3. Conflict resolution#
Because of the way replication works, an original and a replica entry cannot be simultaneously edited. The client will always access the version considered the original entry and replicas are always overwritten in favor of the original. Replication is completely transparent to the client.
When the original is unavailable due to data migration and the client sends a read-only request, the client will be provided with the replica entry. When the original is unavailable due to data migration and the client sends a write request, the cluster will respond with “unavailable” until the migration is complete.
Formally put, this means that quasardb may choose to sacrifice Availability for Consistency and Partitionability during short periods of time.
3.6.4. Impact on reliability#
For an entry x to become unavailable, all replicas must simultaneously fail.
More formally, given a \(\lambda(N)\) failure rate of a node N, the mean time \(\tau\) between failures of any given entry for an x replication factor is:
This formula assumes that failures are unrelated, which is never completely the case. For example, the failure rates of blades in the same enclosure is correlated. However, the formula is a good enough approximation to exhibit the exponential relation between replication and reliability.
Tip
A replication factor of two is a good compromise between reliability and memory usage as it gives a quadratic increase on reliablity while increasing memory usage by a factor two.
3.6.5. Impact on performance#
All add and update (“write”) operations are \(\tau\) slower when replication is active. Read-only queries are automatically load-balanced across nodes containing replicated entries. Depending on cluster load and network topology, read operations may be faster using data replication.
Replication also increases the time needed to add a new node to the ring by a factor of at most \(\tau\).
3.6.6. Fault tolerance#
All failures are temporary, assuming the underlying cause of failure can be fixed (power failure, hardware fault, driver bug, operating system fault, etc.). In most cases, simply repairing the underlying cause of the failure then reconnecting the node to the cluster will resolve the issue.
The persistence layer is able to recover from write failures, which means that one write error will not compromise everything. Disabling the write cache with the “sync” option will further increase reliability.
However, there is one case where data may be lost:
A node fails and
Data is not replicated on another node and
The data was not persisted to disk or storage failed
Note that this can be mitigated using data replication. Replication ensures a node can fully recover from any failure and should be considered for production environments.
3.6.7. Memory Cache and Eviction#
In order to achieve high performance, quasardb keeps as much data as possible in memory. However, a node may not have enough physical memory available to hold all of its entries in RAM. You may enable an eviction limit, which will remove entries from memory when the cache reaches a maximum number of entries or a given size in bytes. See our documentation on permance tuning for more information on how to enable these.
3.7. Data trimming#
When you remove an entry in quasardb, it’s not actually deleted but a new version of the entry is added, flagging the entry as deleted. The actual data removal occurs in an operation called trimming.
When quasardb trims an entry, it will discard old versions in memory and on disk. Trimming is done automatically at the best time, as priority is given to reading and writing data.
Once the entry is trimmed, quasardb will signal the persistence layer to discard the old data, which will result in actually freeing up disk space. This phase is called compacting. The quasardb daemon will log when it requests the persistence layer to compact itself.
That is why when you remove entries from quasardb, the disk usage may not be immediately reduced. It can take up to ten minutes for the disk usage to actually be reduced.
You can request the whole cluster to trim everything immediately with the cluster_trim command from the shell. For more information, please see our documentation on cluster trimming.